Built on a unified lakehouse
The Exclave architecture centers on three core pillars: a digital twin for safe analytics, a transformation engine for reliable data pipelines, and an enrichment layer that adds intelligence and governance.
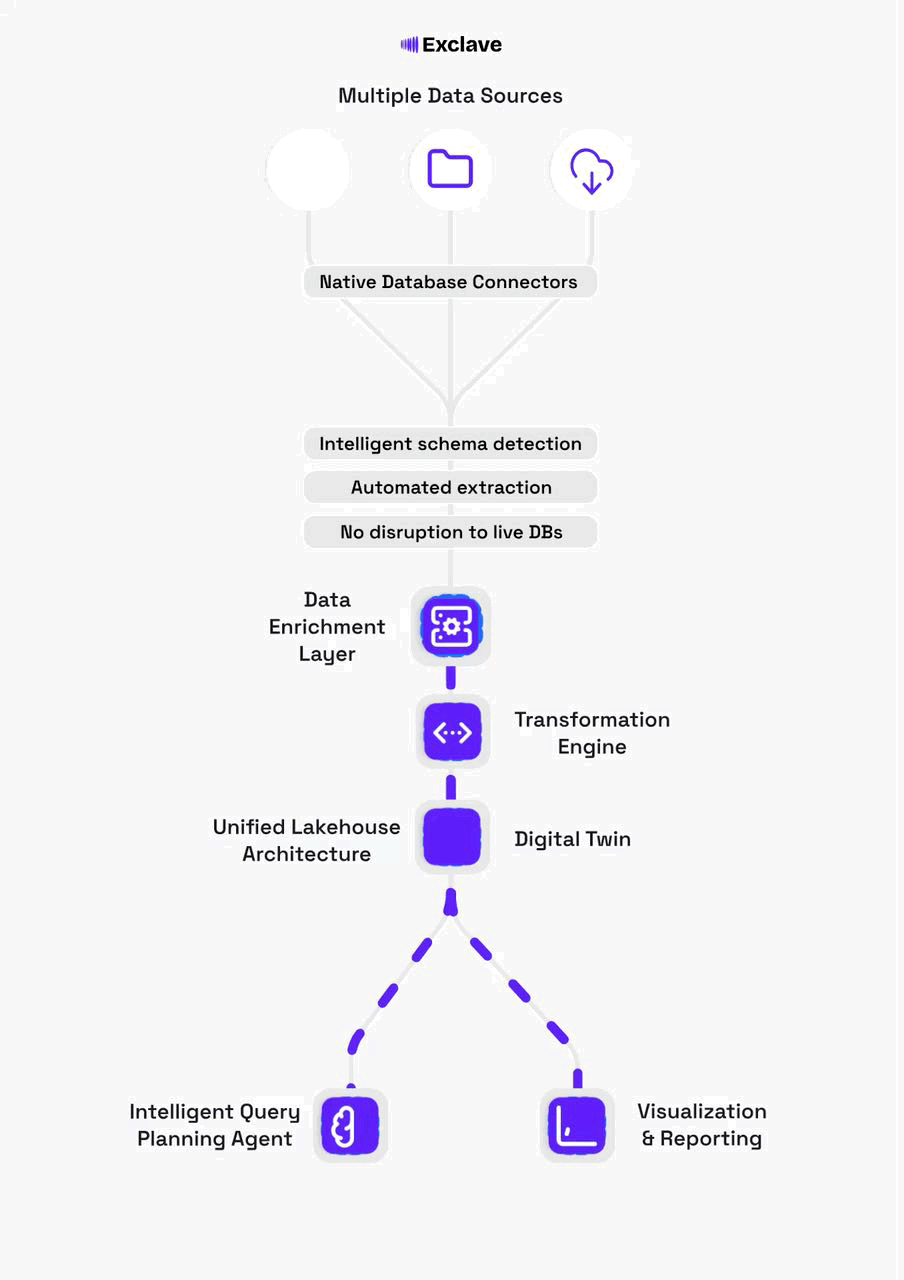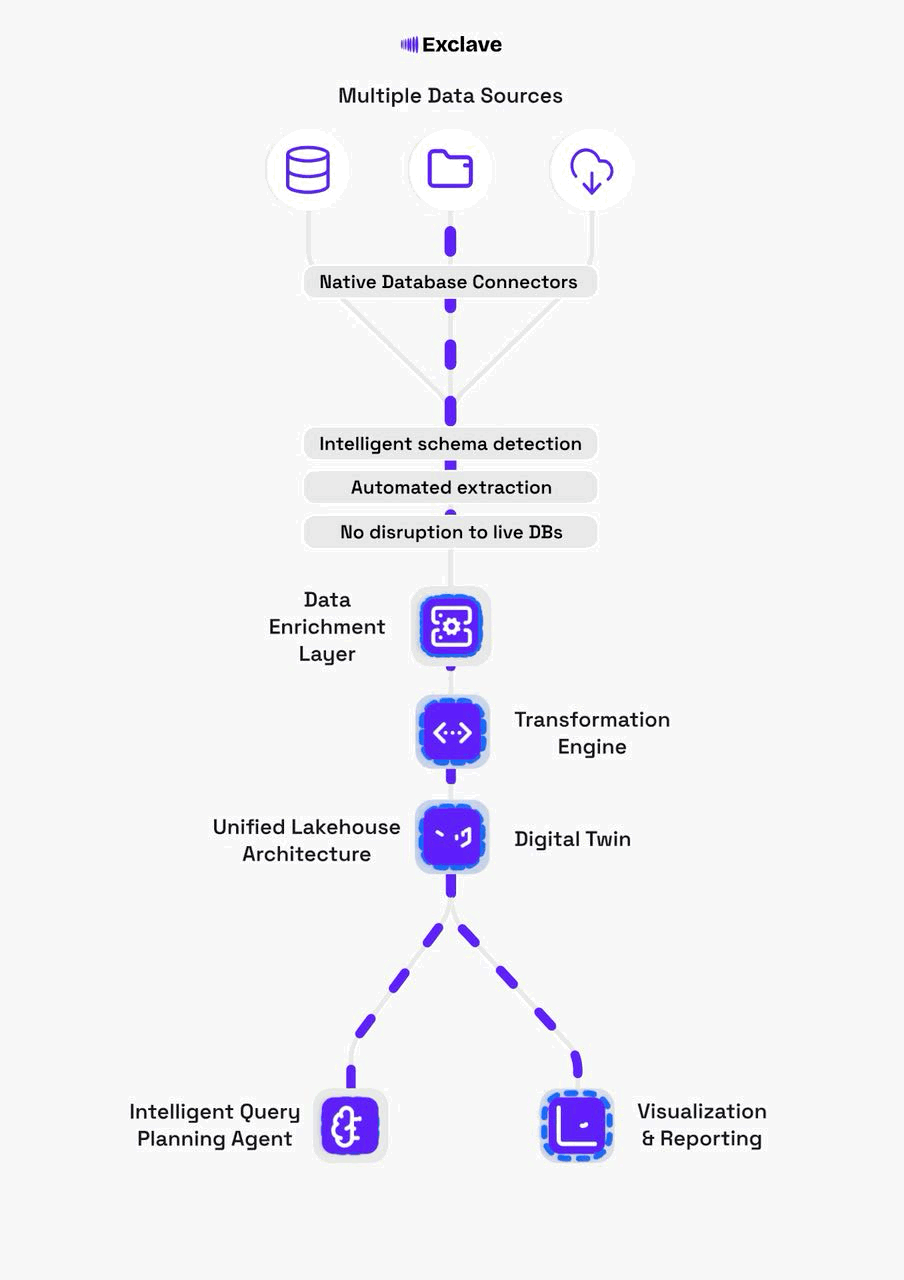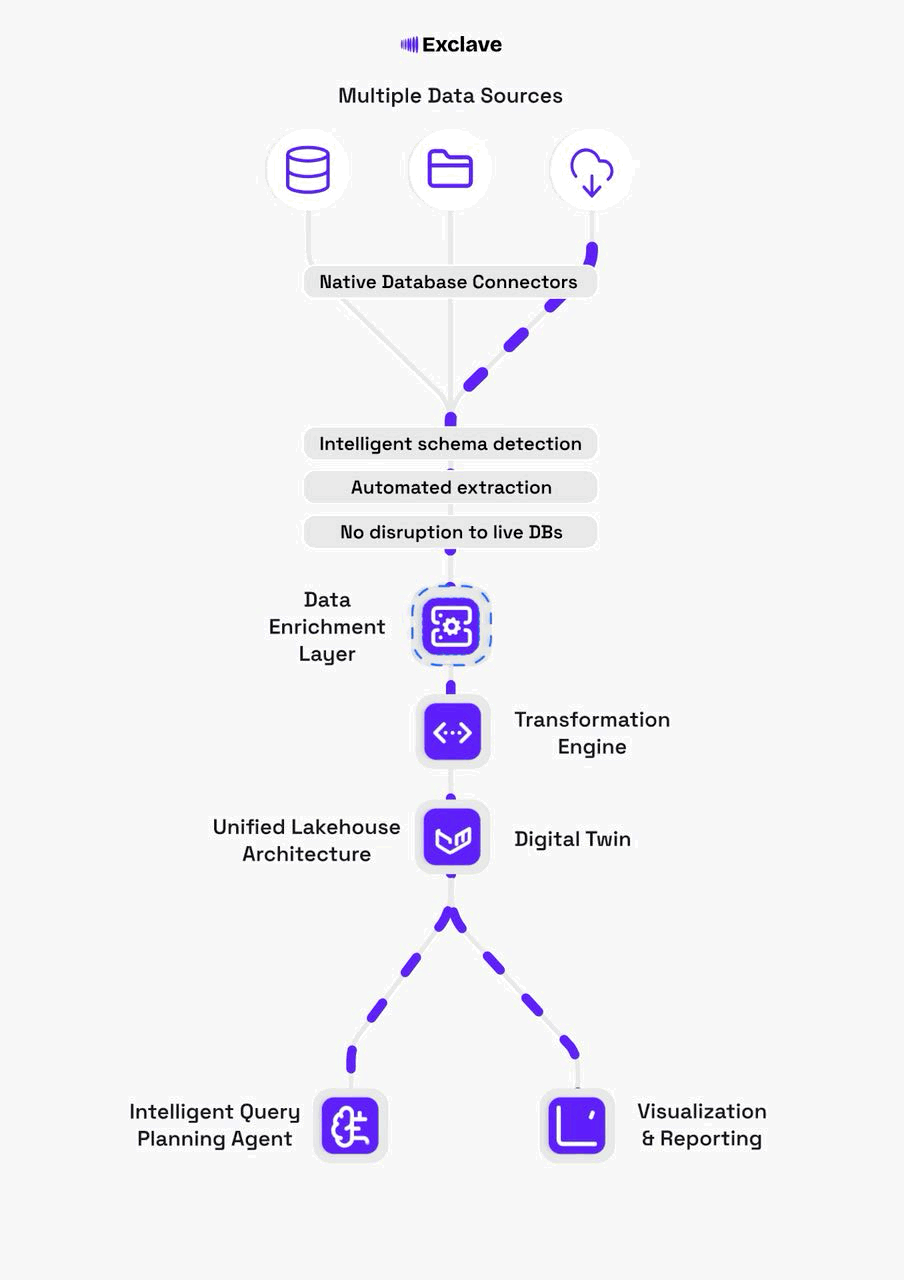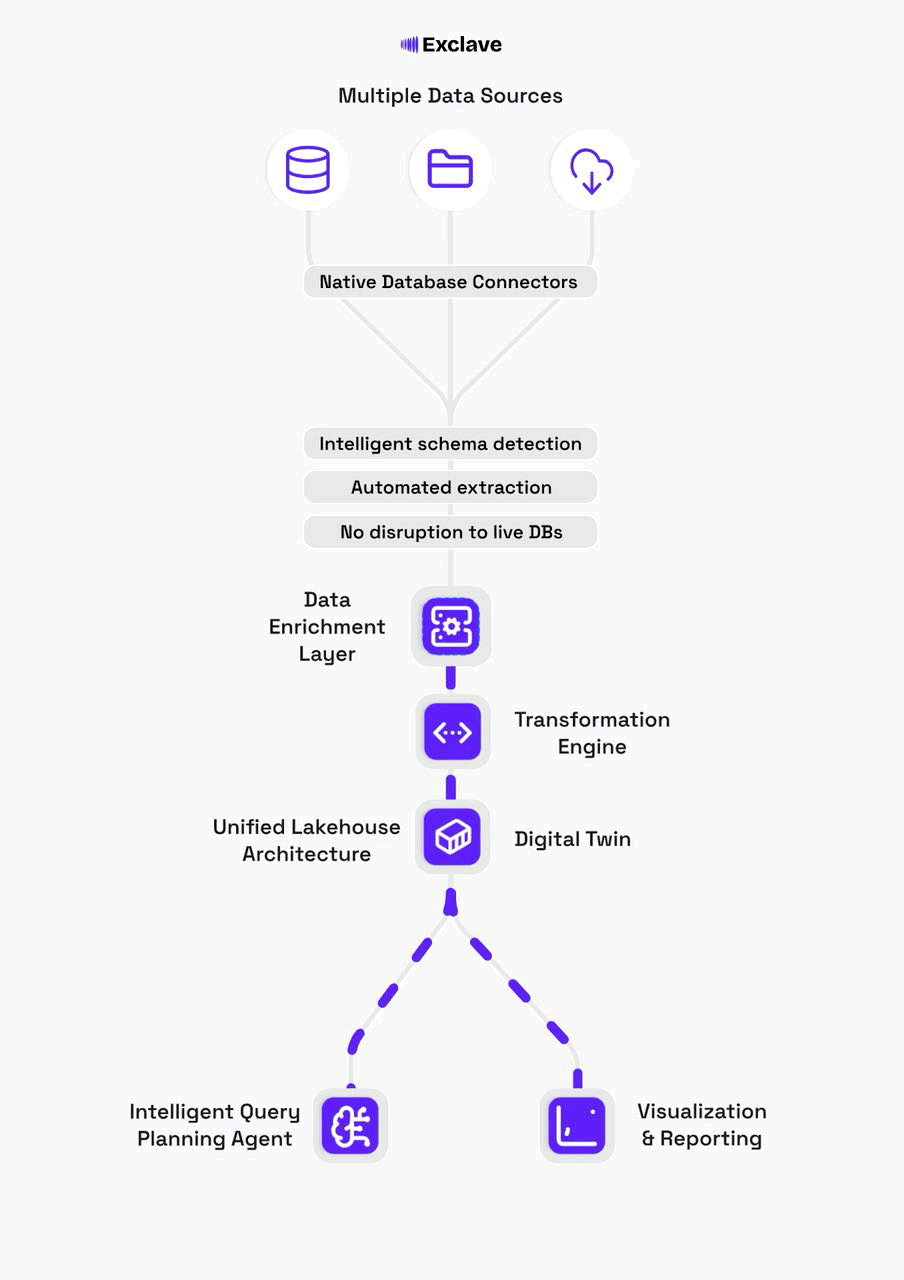
A faithful, continuously-synced mirror of your operational database schemas and data. Run analytics, test migrations, and experiment without any risk to production systems.
- • Schema mirroring with CDC streams
- • Point-in-time snapshots for auditing
- • Isolation from production workloads
- • Cost-efficient storage on object stores
SQL- and Python-native transformations with versioning, testing, and automated lineage tracking. Build reliable, maintainable data pipelines with GitOps workflows.
- • Declarative SQL & Python transforms
- • Built-in testing and validation
- • Automatic lineage and impact analysis
- • Version control integration (Git)
Semantic modeling, feature stores, and quality rules enhance raw data for analytics and ML. Consistent definitions across all consumers ensure reliable insights.
- • Semantic layer (metrics, dimensions)
- • Feature store for ML pipelines
- • Data quality rules and validation
- • Business glossary and documentation
Technical Architecture
Encryption: End-to-end encryption for data in transit and at rest (AES-256)
Access Control: Row-level security, column masking, and RBAC integration
Audit Logging: Complete audit trails for compliance (SOC 2, GDPR, HIPAA)
Data Lineage: Track data from source to dashboard for impact analysis
Query Optimization: Automatic query rewriting and plan optimization
Intelligent Caching: Result caching and materialized views
Distributed Compute: Horizontal scaling for large workloads
Adaptive Throttling: Prevents production database overload
CDC Streaming: Real-time change capture via log-based replication
Incremental Snapshots: Efficient initial loads and refreshes
Schema Evolution: Automatic detection and adaptation to DDL changes
Multi-Source Joins: Query across heterogeneous databases
Open Formats: Apache Iceberg, Parquet for interoperability
Tiered Storage: Hot, warm, cold tiers optimize cost and performance
Compression: Columnar compression reduces storage by 10-20x
Time Travel: Query historical data states for audits and analysis
How Exclave Works
Connect to Data Sources
Point Exclave at your operational databases (Postgres, MySQL, MongoDB, etc.). Native connectors automatically discover schemas, tables, and relationships.
Build the Digital Twin
Exclave creates a faithful mirror in a cost-efficient lakehouse. CDC streams keep the twin in sync in real-time without impacting production.
Transform & Enrich
Apply SQL/Python transformations, define semantic models, and set quality rules. All changes are versioned and tracked with lineage.
Query with Confidence
Use the agentic query planner to generate optimized execution plans. Connect BI tools, notebooks, or build applications—all with governance built in.